To The Bone
“Once we’ve made sense of our world,
we wanna go fuck up everybody else’s
because his or her truth doesn’t match mine.
But this is the problem.
Truth is individual calculation.
Which means because we all have different perspectives,
there isn't one singular truth, is there?”
– Steven Wilson en “To the bone”
Para Steven Wilson el sentido de muchas de las canciones de su quinto álbum, “To The Bone”, tienen que ver con la verdad, concebida como algo que puede ser manipulado y filtrado para significar lo que mejor nos convenga, ya seas un político, un terrorista o simplemente alguien que trata de autoconvencerse de que su relación está bien, a pesar de que no es así.
Podríamos decir que de existir, la verdad debe ser algo en lo que estemos todos de acuerdo, es decir, nadie debería cuestionar una verdad, pero no es tan fácil. La verdad no se define por consenso, ¿o sí?
Incluso en el mundo lógico y bi estable de los computadores el consenso no es algo fácil de definir. Y de eso vamos a hablar en esta oportunidad.
Los computadores del transbordador espacial
Cuando era adolescente leí una nota sobre los transbordadores espaciales, en que se decía que estas naves espaciales contaban con un conjunto de cuatro computadores, trabajando de manera redundante, de este modo se le proporcionaba tolerancia a fallas a todo el sistema. Si un computador presentaba algún desperfecto, los otros tres detectaban esta situación y desconectaban al computador fallido. El mecanismo en que estos computadores detectaba esta situación era algo que me intrigó y que tardé varios años en conocer y comprender en detalle.

Lanzamiento de la misión STS-124 del Discovery, durante esta misión se produjo una falla bizantina entre sus cuatro computadores
En la época en que se diseñaron los transbordadores espaciales la teoría de sistemas redundantes apenas existía. Se dice que la NASA estableció cómo prioridad el resolver el problema de sincronización entre estos computadores. En particular lo más complicado era determinar, de manera efectiva, cuándo uno de los computadores debía tomar el control y desactivar a los otros ante una falla.
Una de las claves al planificar la redundancia es determinar cuántos computadores se requieren para alcanzar cierto nivel de seguridad. Una solución es considerar cinco computadores. Si uno falla, las operaciones siguen de forma normal. Cuando dos computadoras fallan estamos ante lo se llama una situación “fail-safe”, dado que los otros tres previenen la situación temida en sistemas computacionales duales (uno está fallando, pero, ¿cuál?)1. A pesar de estas consideraciones en la NASA usaron cuatro computadores y no cinco.
El problema general es cómo manejar la situación en que componentes fallidas entregan información en conflicto a diferentes partes del sistema. En 1981 un grupo de investigadores de Stanford abordaron este problema en un famoso artículo con título curioso: “El Problema de los Generales Bizantinos”2.

Leslie Lamport, ganador del Premio Turing, autor de LaTeX y coautor principal del artículo sobre los generales bizantinos
El Problema de los Generales Bizantinos
“We’re drilling through their stone
Ho-oh, down through every fairy story”
Leslie Lamport y sus colegas, autores del artículo mencionado, expresaron el problema mediante un experimento mental:
“Un grupo de generales del ejercito bizantino acampan sus tropas alrededor de una ciudad enemiga. La comunicación sólo se puede realizar a través de mensajeros, y los generales deben ponerse de acuerdo en un plan de batalla común. Sin embargo, uno o más de ellos pueden ser traidores que tratarán de confundir a los otros. El problema es encontrar un algoritmo que asegure los generales leales alcanzarán un acuerdo.”
En conjunto con Robert Shostak y Marshall Pease, Lamport mostraron las condiciones que se deben cumplir para resolver este problema. En particular, el problema usando simples mensajes orales, sólo se puede resolver si más de dos tercios de los generales son leales.
Para ordenar un poco las cosas, supondremos que hay n generales, uno de ello es el comandante, y los otros n-1 generales son sus tenientes. De este modo, una forma de expresar este problema es la siguiente:
Un comandante general debe enviar una orden a sus n-1 tenientes generales de modo tal que:
- IC1: Todos los tenientes leales obedecen la misma orden.
- IC2: Si el general comandante es leal, entonces todo teniente leal obedece las ordenes que él envía.
Las condiciones IC1 e IC2 se les llama las condiciones de consistencia interactiva.
Veamos cómo podría operar esto.
Sabemos que hay n generales, un comandante y n-1 tenientes, entonces el comandante envía un mensaje a cada teniente, y a su vez cada teniente comparte sus ordenes con cada colega. Dado esto, cada general debe revisar n-1 mensajes y actuar en base a los mensajes que ha recibido. Por ejemplo, si la mayoría dice que hay que atacar, entonces ataca, si la mayoría dice que hay que retirarse, entonces se retira.
Veamos un ejemplo. En la figura siguiente pueden notar el caso en que hay tres generales y uno de ellos es traidor (puede ser el comandante o uno de los tenientes), en esta configuración uno de los tenientes recibe dos ordenes contradictorias, y en por lo tanto no puede tomar una decisión, el traidor ha logrado paralizar al ejercito.

El caso de tres generales y un traidor, tomado del paper original
La manera de solucionar el problema es usar mensajes infalibles, es decir, textos que no puedan ser alterados por los mensajeros. Para esto, debemos definir tres condiciones que se deben cumplir:
A1. Todo mensaje que se envía es entregado correctamente (es decir, no se puede alterar).
A2. El receptor de un mensaje sabe quien lo despachó.
A3. La ausencia de un mensaje puede ser detectada.
Si se da esto, Lamport y sus colegas muestran que es posible resolver el problema con n = 3m+1 generales. Dada esta condición, los autores muestran un primer algoritmo que garantiza solución si hay a lo más m generales traidores (en términos prácticos, deben haber cuatro o más generales para tener solución).
Traduzcamos esto a la realidad del Tranbordador espacial, donde habían cuatro computadores, y un quinto de reserva. En este contexto una “traición” se traduce como un computador fallando (por ejemplo, entrega información incoherente). Lo que queremos es determinar cuál computador apagar ante esta situación. La primera solución propuesta por Lamport sólo nos permite determinar a lo más la falla de un computador.
Para mejorar esto, Lamport ofrece otra alternativa, un algoritmo en que los mensajes son firmados, en este caso, se puede resolver el caso de los tres generales. Los algoritmos propuestos en el artículo requieren recibir mensajes de todos los generales, o definir una estrategia por defecto ante la pérdida de un mensaje. En el artículo se hace referencia al hecho de que cuando se trata de computadoras, es esencial que estas operen de la misma forma, estén sincronizadas y en lo posible compartan información de modo eficiente. En el caso del transbordador espacial, los procesadores comparte el BUS de datos y durante el desarrollo de este programa espacial se hicieron modificaciones para abordar diversas “fallas bizantinas” que se produjeron3.
La Falla Bizantina del Discovery
Durante la misión STS-124 del transbordador Discovery, en 2008 se produjo una falla que podría haber derivado en un desastre. Durante la carga de combustible se produjo una discrepancia de 3-1 entre los computadores de la nave, esto es, los resultados de uno de los computadores no concordaba con lo informado por los otros tres. A los tres segundos se produjo una partición 2-1-1, es decir, sólo dos computadores estaban de acuerdo, y los otros dos presentaban discrepancias. Esto obligó a detener la cuenta regresiva de lanzamiento.
Mientras se revisaba la situación se llegó a una partición 1-1-1-1, el peor estado posible, ningún computador estaba de acuerdo con los otros tres. Sin embargo, no había ningún problema en los computadores, el fallo estaba en otras componentes del sistema, denominadas MDM Multiplexer/DeMultiplexer. Los MDM son una especie de enrutadores remotos que canalizan todas las señales de I/O de la nave hacia los computadores. La causa del problema era una fractura física en un diodo dentro de uno de los MDM. La figura que sigue muestra la fotografía con la fractura del diodo (cariñosamente apodado “el asesino bizantino”).

La fotografía del Asesino Bizantino
Fallas Bizantinas
“But behind the closed doors
The bees were buzzing
Inciting me to war
You’re penitent maybe
But it’s really not your fault you fail to see”
Decimos que la tolerancia a fallas es bizantina cuando hay información imperfecta para determinar si una componente está fallando. Esto se da principalmente en sistemas distribuidos.
En una “Falla Bizantina”, una componente (por ejemplo, un servidor), puede aparecer de modo inconsistente como funcional o fallida a los sistemas de detección de fallos, es decir, presenta diferentes síntomas a diferentes observadores. En este caso es dificil para las otras componentes de la red declararla como fallida y desconectarla de la red, porque primero se debe alcanzar un consenso para decidir si la componente se considera fallida.
En el caso de la falla en el STS-124 no había falla en ningún computador, pero durante la crisis era imposible determinar esa situación.
Este tipo de fallas no sólo se da en sistemas distribuidos, hay un ejemplo que viene de la biología.
Abejas Bizantinas
Cuando las abejas deben elegir un nuevo hogar para sus reinas, envían exploradoras para buscar un lugar apropiado. Los científicos han encontrado que las abejas llegan a un consenso para decidir el nuevo lugar para la colmena. En diversos experimentos, se pudo determinar que cuando se les ofrece dos alternativas igual de atractivas, las abejas no pueden decidir, y el enjambre se divide y todas las abejas mueren.
Consenso
So pariah you'll begin again
Take comfort from me
And I will take comfort from you
Ahora vamos a discutir cómo evitar que nos ocurra el fatal destino de las abejas, pero antes tenemos que recordar un concepto que discutimos hace un tiempo.
El teorema CAP
Cuando hablamos de sistemas distibuidos nos gustaría garantizar tres cosas:
- COHERENCIA: nos gustaría que todos los nodos tengan una visión coherente del sistema.
- DISPONIBILIDAD (AVAILABILITY): que toda petición sea atendida.
- TOLERANCIA A PARTICIONES: que el sistema funcione incluso si hay pérdida de mensajes.
A estas tres garantias se les llama CAP por sus siglas en inglés (Consistency, Availability, Partitio Tolerance). He hablado antes de este tema en este artículo.
Lo importante a recordar acá es que existe un resultado que nos dice que no podemos contar con las tres garantías al mismo tiempo en un sistema distribuido, a lo más podemos garantizar dos.
Podemos tener estas combinaciones:
- CA: que garantiza sólo respuestas correctas mientras la conexión funcione bien, esto se da en los sistemas centralizados.
- CP: que garantiza respuestas correctas incluso si hay fallas en la conexión, pero la respuesta puede no estar (disponibilidad debil).
- AP: siempre se provee “la mejor” respuesta incluso en presencia de fallas en la conexión (en este caso la coherencia es eventual).

El Teorema CAP y los tipos de combinaciones disponibles sobre las que podemos operar nuestros sistemas distribuidos
Fallas Bizantinas y Tolerancia a Particiones
Cuando se produce una falla bizantina, estamos ante un escenario en que una máquina responde incorrectamente. Para corregir una falla bizantina, en que hay f máquinas fallando, necesitaremos 2f+1 máquinas replicadas.
Para decidir cuál máquina apagar ante una falla bizantina debemos encontrar el consenso. Hay varios tipos de consensos posibles:
- Consenso Fuerte: todas las máquinas, o nodos, deben concordar en sus respuestas.
- Consenso Mayoritario: debe haber concordancia en la mayoría.
- Consenso Plural: cuando una pluralidad concuerda, no necesariamente la mayoría.
- Consenso de Quorum: se define que n nodos deben concordar.
- Consenso Deshabilitado: no nos importa el consenso, nos interesa la primera respuesta que recibamos de algún nodo.
Cuando tenemos Consenso Fuerte el sistema es CP, cuando tenemos Consenso Deshabilitado nos encontramos ante un sistema AP. Y hay una gradualidad desde CP a AP en la medida que vamos relajando el nivel de consenso.
Coherencia
“A sea we can sail
Then sink like a stone
Down to the truth
Down to the bone”
Ya definimos criterios para declarar el consenso, es evidente que no es posible alcanzar un consenso fuerte ante fallas bizantinas, así que a nivel operacional debemos definir un nivel de consenso deseado (por ejemplo, mayoritario, o de Quorum) y de Coherencia.
Si queremos una Coherencia Fuerte (CP) vamos a sacrificar la Disponibilidad del sistema y requeriremos un mayor grado de replicación. Si optamos por la Alta Disponibilidad tenemos que sacrificar la coherencia y no necesitamos tanta replicación.
Para alcanzar la coherencia necesitamos tener mecanismos de distribución de mensajes entre los nodos. Hay varias alternativas, una manera interesante de lograr esto son los protocolos de chismorreo.
Para ejemplificar esto vamos a analizar el caso de Dynamo, un sistema de datos distribuidos creado por Amazon.
Dynamo4 es una base de datos distribuida, donde se puede elegir el factor de replicación por cada tabla. Para alcanzar consenso se utiliza un protocolo tipo Gossip (Chismorreo). Se utiliza Quorums, hay mútiples nodos para lectura (L) y escritura (E). En cada operación al menos L o E nodos deben confirmar la operación. Con L o E más alto se logra mayor coherencia, sacrificando disponibilidad.
Un protocolo de chismorreo, o Protocolo Gossip, es una forma de esparcir los mensajes por la red del mismo modo en que funcionan los rumores, o cómo se distribuyen las epidemias.
La idea es muy simple, veamos cómo se esparcen los rumores en una oficina, por ejemplo, Alicia decide esparcir un rumor, entonces se acerca a la cafetería del piso y encuentra a Benito y le cuenta el chisme. Ambos vuelven a sus puestos de trabajo, el algún momento Benito se encuentra con Carlos, o Alicia encuentra a Daniela y distribuyen el rumor, y así sigue propagándose a través de encuentros aleatorios.
Un protocolo gossip es uno que satisface las siguientes condiciones:
- El núcleo del protcolo involucra interacciones periódicas entre pares..
- La información intercambiada durante estas interacciones es de un tamaño fijo y acotado.
- Cuando los participantes, o agentes, interactúan, el estado de un agente cambia para reflejas el estado del otro.
- No se debe asumir que las comunicaciones son confiables.
- La frecuencia de las interacciones es baja, comparada con la latencias de modo que los costos del protocolo son despreciables.
- Hay algún grado de azar en la selección de los pares. Los pares son seleccionados del conjunto de todos los nodos o de un conjunto pequeño de vecinos.
- Debido a la replicación a una redundancia implícita en el despliegue e la información.
Los protocolos gossip son muy eficientes, sobretodo porque las estructuras de sistemas distibuidos masivos pueden ser complejas y enormes, y esta es una manera muy efectiva de diseminar información rápidamente a un costo razonable.
Detectando inconsistencias
“Hold on, down and deeper, down we’re going
Way down through the floor
Oh, don’t you wanna see what's at the core?”
Cómo en Dynamo los datos se encuentran distribuidos puede ocurrir que dos nodos tengan datos inconsistente entre sí. Dynamo tiene un mecanismo para detectar esta inconsistencia e informarla, aunque el proceso de reconciliación, es decir, al decisión de cuál es el valor que debería considerarse como válido es algo que debe decidir la aplicación que usa Dynamo como almacenamiento.
Para detectar inconsistencias Dynamo utiliza una estructura de datos conocida como Árboles de Merkle (Merkle Tree).
Esta estructura de datos permite detectar inconsistencias rápidamente y minimizar la cantidad de datos a transferir. Un árbol de Merkle es un árbol que almacena los valores de una una función de hash aplicado a llaves individules. Los nodos padres de más arriba del árbol contienen el valor de hash de sus respectivos hijos. La ventaja principal del Arbol de Merkle, es que cada rama puede ser verificada independientemente, si que un nodo tenga que descargar el árbol entero o todo el conjunto de datos. Por ejemplo, si el valor de hasho de la raiz de dos árboles son iguales, entonces lo valores de los nodos hojas en el árbol son iguales y no se requiere sincronizar los nodos. Si no, esto implica que los valores de algunas réplicas son diferentes. En tal caso, los nodos pueden intercambiar los valores de hash de los hijos y el proceso continua hasta alcanzar las hojas del árbol. En ese punto los servidores pueden detectar las llaves que están desincronizadas.
Dynamo usa los Arboles de Merkle como sigue: cada nodo mantiene un árbol de Merkle separado por cada rango de llaves cubiertas por el nodo. Esto le permite a los nodos comaprar si sus llaves están actualizadas. En este esquema, dos nodos intercambian las raices de sus árboles correspondientes a las llaves que mantienen en común. Y así, sucesivamente, atravesando el árbol del modo descrito recién, los nodos determinan si hay diferencias y se ejecutan las acciones de sincronización apropiadas. La desventaja de esto es que muchas llaves cambian cuando un nodo se uno o se aleja del sistema, lo que requiere que estos árboles sean recalculados.
Las siguientes tres figuras5, muestran cómo se usa todo esto para mantener consistencia en Dynamo:

Árboles de Merkle usados en Dynamo
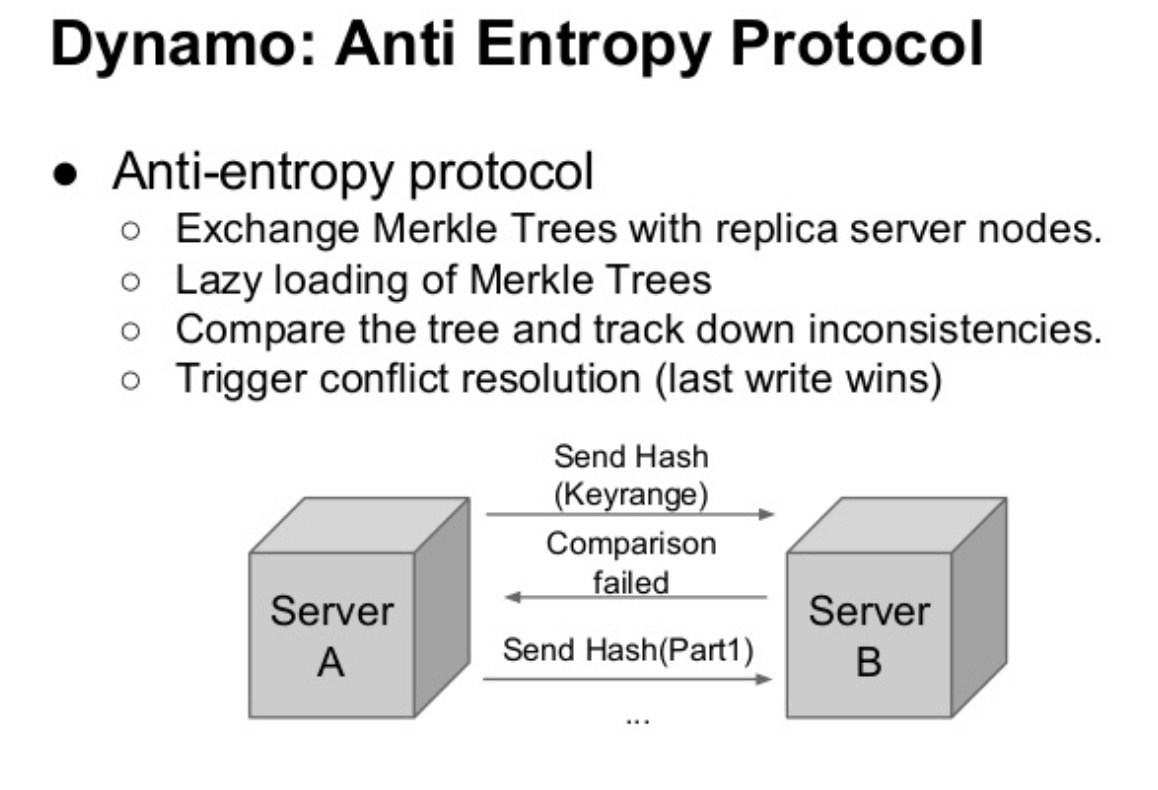
Protocolo anti entropía de Dynamo, los servidores intercambian sus árboles de Merkle, comparan primero las raices y luego revisan las inconsistencias navegando las ramas del árbol.

El protocolo Gossip asegura que eventualmente todos los nodos compartan la misma visión del sistema, o se detecte una falla o inconsistencia.
Truth is individual calculation
En los sistemas distribuidos no hay una fuente central de autoridad, el estado del sistema depende de resolver las inconsistencias que se pueden producir, En particular, ante la presencia de fallas bizantinas, se hace necesario definir mecanismos que permitan administrarlas y determinar esas situaciones. Hemos visto cómo un sistema distribuido, como Dynamo, aborda este problema de alcanzar consenso ante la posibilidad de fallas bizantinas. Cómo podrán notar es algo bastante complejo que ha requerido el desarrollo de técnicas bastante ingeniosas para resolverlo.
Lo más importante que quiero transmitir en este post, es la idea que en sistemas distribuidos el consenso es el fruto del cálculo individual de cada nodo, o como dice Steven Wilson:
Truth is individual calculation. Which means because we all have
different perspectives, there isn’t one singular truth, is there
Notas:
Los epígrafes en inglés están tomados de las siguientes canciones del disco “To The Bone” de Steven Wilson: “To The Bone”, “Pariah” y “People who eat darkness”.
Computers in Spaceflight: The NASA Experience https://history.nasa.gov/computers/Ch4-4.html ↩︎
The Byzantine Generals Problem, http://bnrg.cs.berkeley.edu/~adj/cs16x/hand-outs/Original_Byzantine.pdf ↩︎
https://c3.nasa.gov/dashlink/projects/79/wiki/test_stories_split/ ↩︎
Dynamo: Amazon’s Highly Available Key-value Store https://www.allthingsdistributed.com/files/amazon-dynamo-sosp2007.pdf ↩︎
https://www.slideshare.net/yellow7/cassandra-backgroundandarchitecture](https://www.allthingsdistributed.com/files/amazon-dynamo-sosp2007.pdf) ↩︎
Comentarios
comments powered by Disqus